gpu计算
异构计算
异构计算,首先必须了解什么是异构,不同的计算机架构就是异构,按照指令集划分或者按照内存结构划分。
GPU 本来的任务是做图形图像的,并行度很高,一定距离外的像素点之间的计算是独立的,所以属于并行任务。GPU 插在主板的 PCIe 卡口上,运行程序的时候,CPU 像是一个控制者,指挥两台 显卡完成工作后进行汇总,和下一步工作安排,所以 CPU 我们可以把它看做一个指挥者,主机端,host,而完成大量计算的 GPU 是我们的计算设备,device。
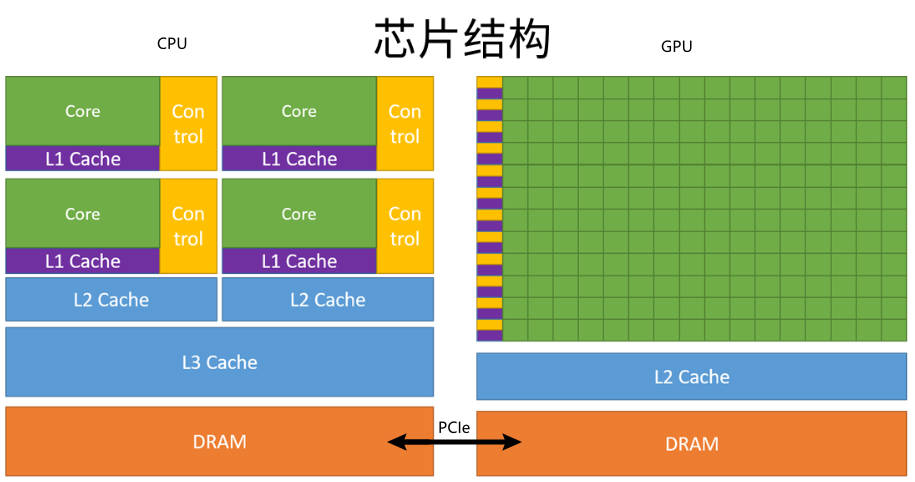
上面这张图能大致反应 CPU 和 GPU 的架构不同。
左图:一个四核 CPU 一般有四个 ALU,ALU 是完成逻辑计算的核心,也是我们平时说四核八核的核,控制单元,缓存也在片上,DRAM 是内存,一般不在片上,CPU 通过总线访问内存。
右图:GPU,绿色小方块是 ALU,我们注意红色框内的部分 SM,这一组 ALU 共用一个 Control 单元和 Cache,这个部分相当于一个完整的多核 CPU,但是不同的是 ALU 多了,Control 部分变小。所以计算能力提升了,控制能力减弱了。所以对于控制密集的程序,一个 GPU 的 SM 是没办法和 CPU 比较的,但是对了逻辑简单,数据量大的任务,GPU 更高效。并且,一个 GPU 有好多个 SM。
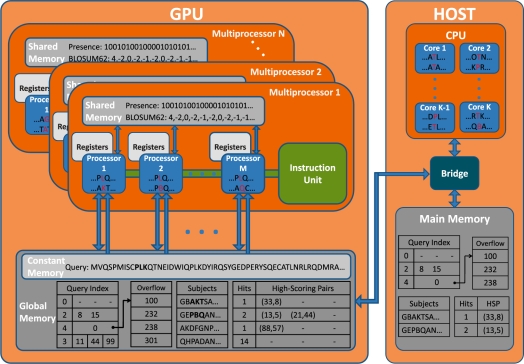
CPU和GPU之间通过 PCIe 总线连接,用于传递指令和数据,这部分也是后面要讨论的性能瓶颈之一。
一个异构应用包含两种以上架构,所以代码也包括不止一部分:
- 主机代码在主机端运行,被编译成主机架构的机器码
- 设备端的在设备上执行,被编译成设备架构的机器码。
所以主机端的机器码和设备端的机器码是隔离的,自己执行自己的,没办法交换执行。
主机端代码主要是控制设备,完成数据传输等控制类工作,设备端主要的任务就是计算。
因为当没有 GPU 的时候 CPU 也能完成这些计算,只是速度会慢很多,所以可以把 GPU 看成 CPU 的一个加速设备。
GPU 硬件结构
GPU的硬件结构,也不是具体的硬件结构,就是与 CUDA 相关的几个概念:thread,block,grid,Wrap,SP,SM。
-
SP:最基本的处理单元,streaming processor。最后具体的指令和任务都是在 SP 上处理的。GPU 进行并行计算,也就是很多个 SP 同时做处理。每个 SP 有它自己的寄存器,比较稀缺的资源。
-
SM:多个(几十或者上百,取决于设备) SP 加上其他的一些资源组成一个 SM,streaming multiprocessor。其他资源也就是存储资源,共享内存,寄储器等。各个 SM 之间只能通过全局内存间接通信,没有其它互联通道,所以这个集群只适合进行纯并行化计算。如果在计算过程中每个 SM 之间还需要通信,则整体运行效率很低。
-
Wrap:
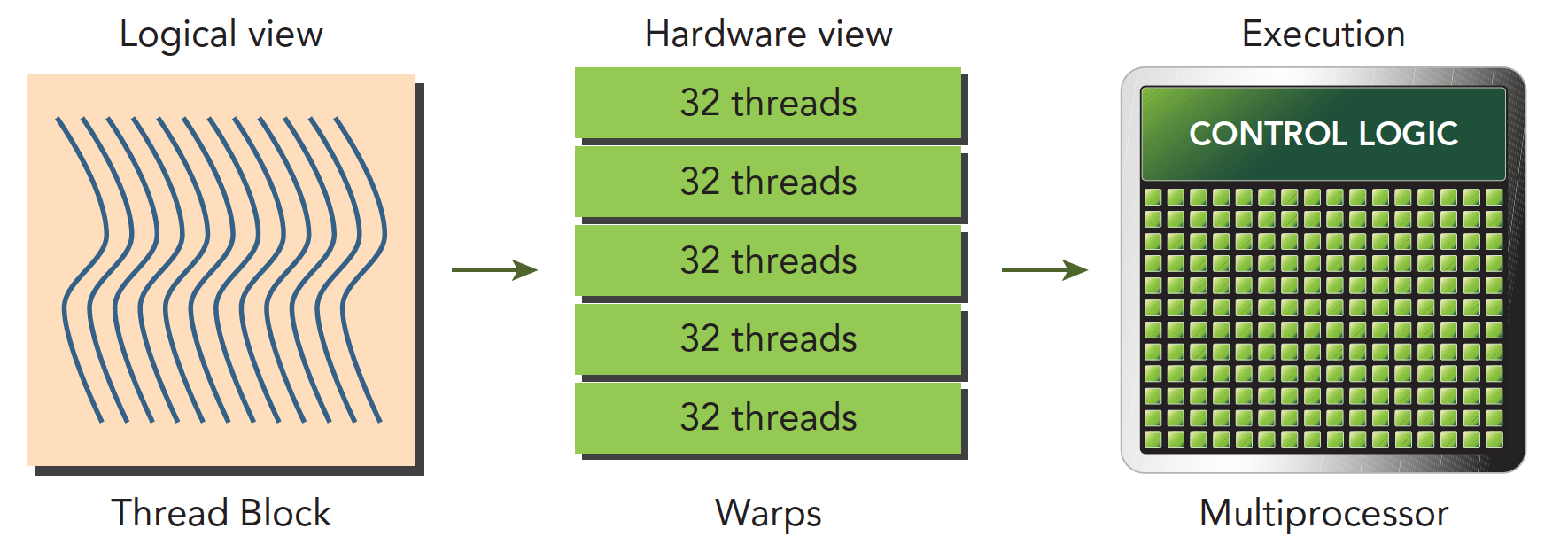
- SM 中的 SP 会分成成组的 Warp,每组 32 个。
- Wrap Scheduler 会从在 SM 上的所有 Warp 中进行指令调度。从已经有指令可以被执行的 Warp 中挑选然后分配下去。这些 Warp 可能来自与驻留在 SM 上的任何线程块。
- 所以,Warp 是 GPU 执行程序时的调度单位,同在一个 Wrap 的线程,以不同数据资源执行相同的指令。
- 一个 SM 上在某一个时刻,有 32 个线程在执行同一条指令,这 32 个线程可以选择性执行,虽然有些可以不执行,但是他也不能执行别的指令。
- 当一个 Warp 空闲时(或者在读数据,或者执行完),SM 就可以调度驻留在该 SM 上的另一个 Warp。
- 并发的 Warp 之间切换是没消耗的,因为资源早就被分配到所有 thread 和 block。
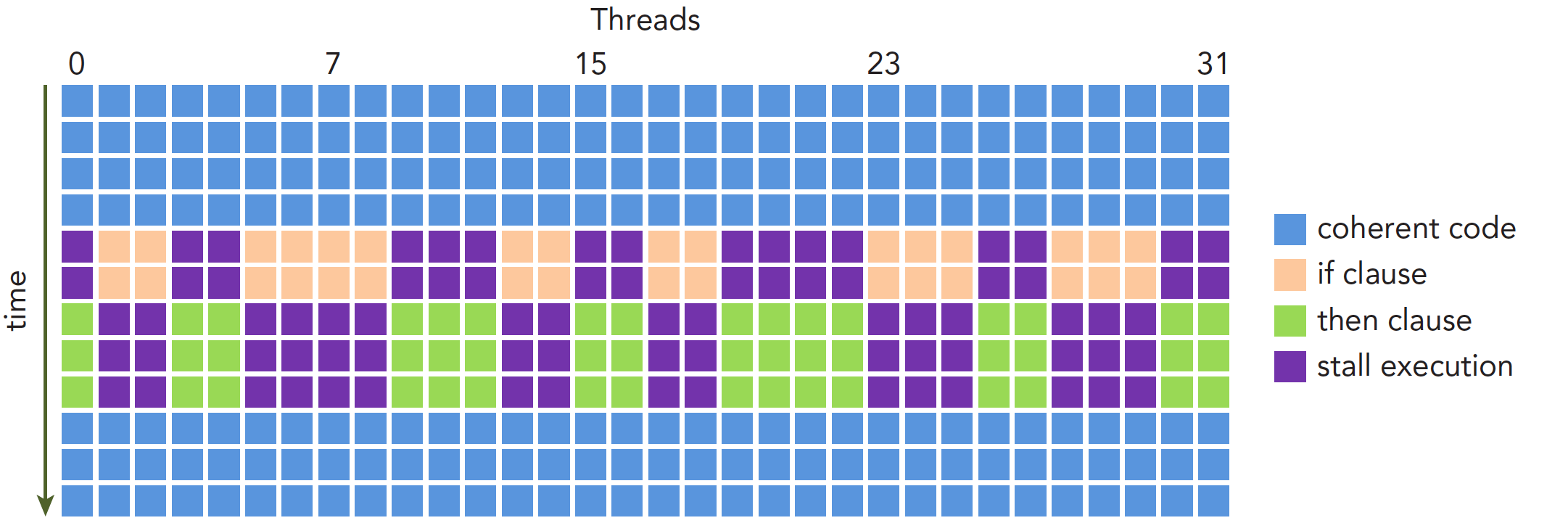
如上图,如果有 if-else 分支,同一个 Warp 内的线程,不能在执行 if 的同时,另一群在执行 else,而是在执行 if 时,另一群选择等待。这种现象又被称为 Warp 发散。
- grid、block、thread:在利用 cuda 进行编程时,一个核函数会分配一个 grid。一个 grid 分为多个 block,而一个 block 分为多个 thread。其中任务划分到是否影响最后的执行效果。划分的依据是任务特性和 GPU 本身的硬件特性。
- block 是软件概念,通过设置该属性告诉 GPU 我有多少个线程,该如何组织。
- 一个 block 只会由一个 SM 进行调度,一旦被分配好 SM,block 就会一直驻留在 SM 中直到程序结束。
- 一个 SM 可以拥有多个 block,但是要顺序执行:
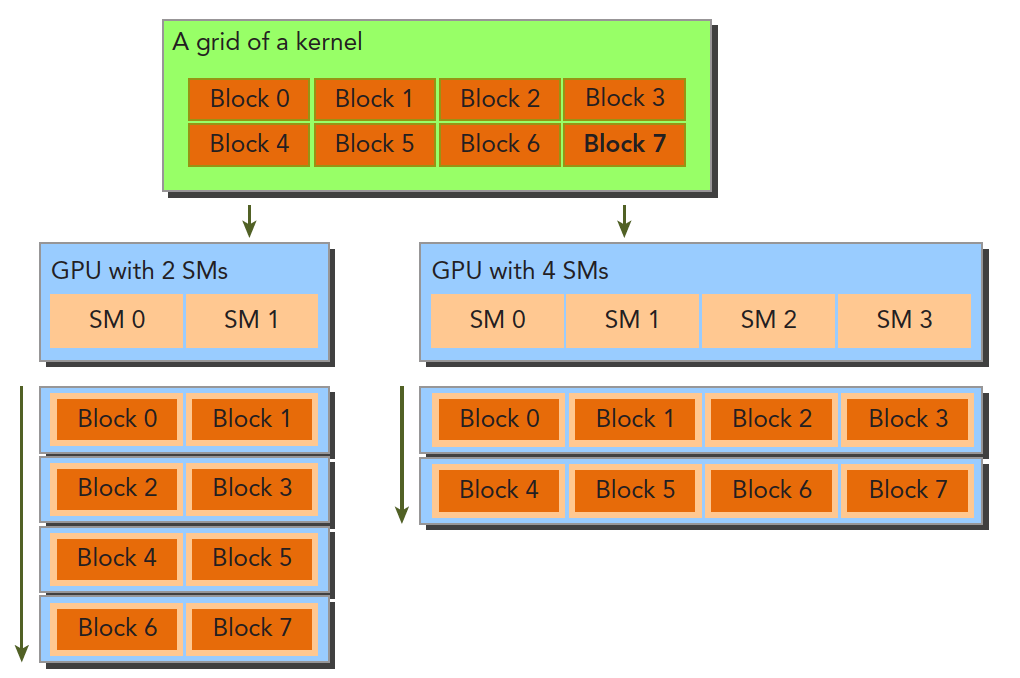
- 一个 block 有多个 Warp,例如一个有 512 线程的 block,有(512 / 32 = 16)个 Warp,这些 Warp 轮流进入 SM,由 Warp Scheduler 负责调度。若 block 内的线程数不是 32 的整数倍,那多余的 thread 单独为一个 Warp。
- 目前一个 block 内最多 1024 个线程。