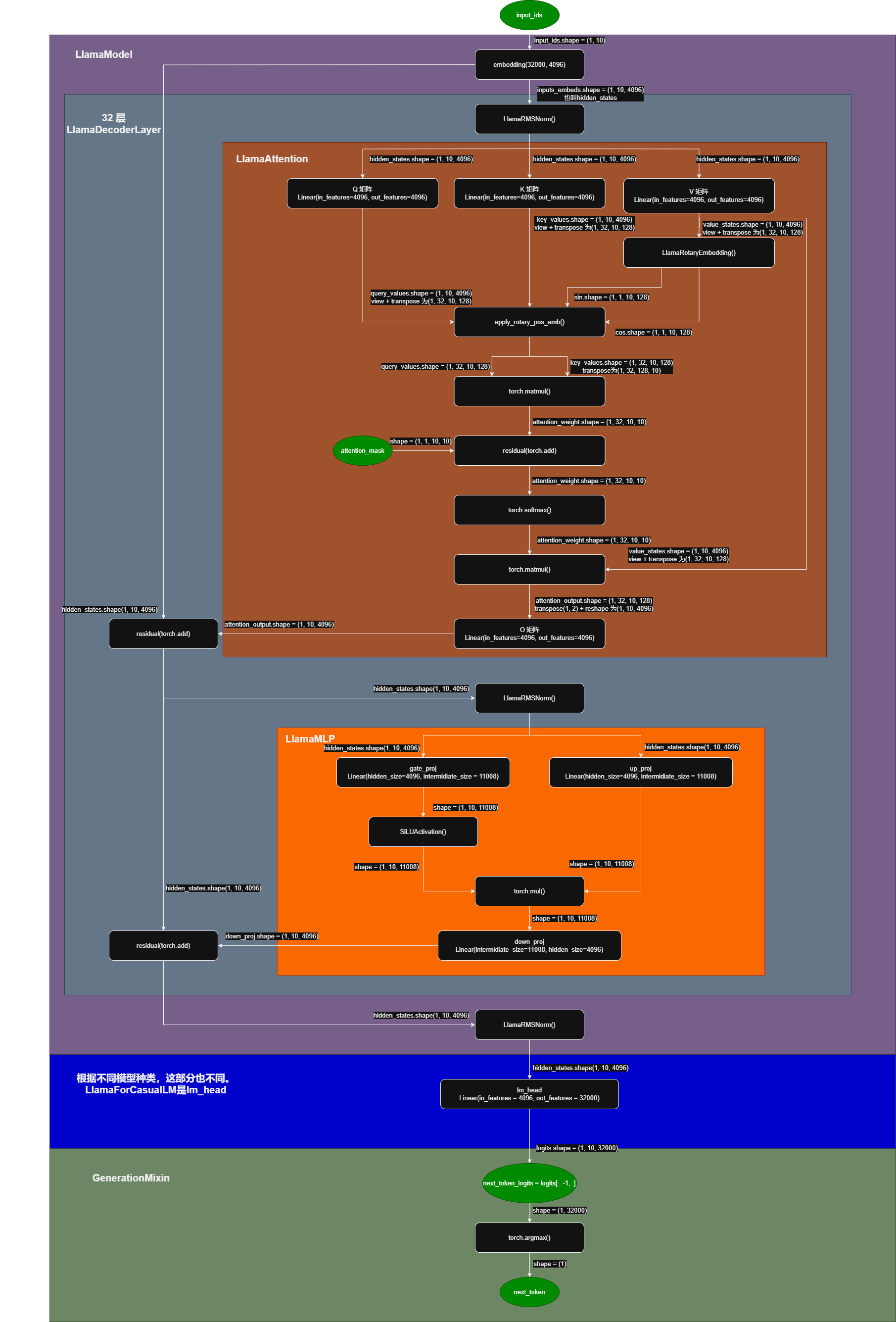
mHC Manifold-Constrained Hyper-Connections
流形约束超连接,是 DeepSeek 团队在 2025 年 12 月提出,在 2026 年 4 月发布的 DeepSeek V4 中应用的新的残差技术,是 DeepSeek 的核心创新之一。他的目标是为了解决传统残差连接表达能力不足以及使用原始超链接(Hyper-Connections)深层次训练崩溃的问题。
计算流程
以下代码来自 sglang 中的 deepseek v4 的 forward函数,省略了部分细节。
1 | residual = hidden_states |
可以看见,在最开始的时候会保存原始的 hidden_states(residual),之后对这部分 hidden_states 做预处理。
hc_pre
对于 hc_pre 函数,可以看到有四个入参。
输入参数:
| 参数 | 类型 | 维度 | 说明 |
|---|---|---|---|
| x | torch.Tensor | […, hidden_size] | 输入激活值,通常是上一层输出 |
| hc_fn | torch.Tensor | [hc_mult, hidden_size] | 混合函数权重,定义了如何将输入映射到混合空间 |
| hc_scale | torch.Tensor | [hc_mult] | Sinkhorn 迭代的缩放因子 |
| hc_base | torch.Tensor | [hc_mult] | Sinkhorn 迭代的基础偏置项 |
返回值:
| 参数 | 类型 | 维度 | 说明 |
|---|---|---|---|
| y | torch.Tensor | […, hidden_size] | 预处理输出:对 x 按混合权重加权后的结果 |
| post | torch.Tensor | […, hc_mult] | 后处理权重:用于后续 hc_post 阶段 |
| comb | torch.Tensor | […, hc_mult, hc_mult] | 组合矩阵:表示各混合通道间的连接关系 |
具体计算分为两个步骤:
- 计算输入的归一化(rmsnorm),并与混合函数矩阵乘,映射得到混合权重。
1 | def hc_pre_torch_impl(x, hc_fn): |
这个函数将返回 mixes 交给下一步处理。
- Sinkhorn 归一化
Sinkhorn 归一化是一种快速迭代算法,用来将任意非负矩阵转换成双随机矩阵(每行和每列的和都等于 1)。它是 DeepSeek V4 mHC(流形约束超连接)架构中最核心的数学创新,解决了原始超连接训练崩溃的问题。hc_split_sinkhorn 的作用是将输入的 mixes 张量拆分为三部分(pre、post、comb),并对 comb 部分执行 Sinkhorn 归一化,使其收敛为双随机矩阵(doubly stochastic matrix)。
核心思想:交替对行和列进行归一化,直到收敛。
1 | pre, post, comb = hc_split_sinkhorn( |
输入参数:
| 参数名 | 类型 | 维度 | 输入/输出 | 说明 |
|---|---|---|---|---|
| mixes | float32 | (n, mix_hc) | 输入 | 混合参数,其中 mix_hc = (2 + hc) * hc |
| hc_scale | float32 | (3,) | 输入 | 三部分(pre/post/comb)的缩放系数 |
| hc_base | float32 | (mix_hc,) | 输入 | 基础偏置参数 |
| hc_mult | int | 标量 | 输入 | 隐藏维度参数,控制 pre/post/comb 的输出维度 |
| hc_sinkhorn_iters | int | 标量 | 输入 | Sinkhorn 归一化的迭代次数 |
| hc_eps | float | 标量 | 输入 | 数值稳定性参数,防止除零,用于 sigmoid 和归一化 |
输出参数:
| 参数名 | 类型 | 维度 | 输入/输出 | 说明 |
|---|---|---|---|---|
| pre | float32 | (n, hc) | 输出 | 前置参数,sigmoid 激活结果 |
| post | float32 | (n, hc) | 输出 | 后置参数,sigmoid 激活结果乘以 2 |
| comb | float32 | (n, hc, hc) | 输出 | 组合矩阵,经过 Sinkhorn 归一化的双随机矩阵 |
其中输出的 pre 和 post 是由 mixes、hc_scale 以及 hc_base 计算得到的:
在分出这三个 tensor 后,对最后一个 combination tensor 进行迭代的归一化:
1 | def sinkhorn_normalize(comb_frag: torch.Tensor, sinkhorn_iters: int, eps: float = 1e-6): |
hc_post
将注意力/FFN 的输出与残差进行加权组合,是 hc_pre 的逆操作。该部分是对 mhc 部分的后处理函数:
1 | def hc_post_torch_impl(x, residual, post, comb): |
输入参数:
| 参数 | 形状 | 含义 |
|---|---|---|
| x | (n, hidden_dim) | 当前层输出 |
| residual | (n, hc_mult, hidden_dim) | 来自 hc_pre 的多路残差 |
| post | (n, hc_mult) | 后处理权重 |
| comb | (n, hc_mult, hc_mult) | 组合权重矩阵 |
输出参数:
| 参数 | 形状 | 含义 |
|---|---|---|
| output | (n, hc_mult, hidden_dim) | 当前层输出 |
| 公式: |
总结
mhc 诞生主要为了解决:
- 传统残差连接表达能力不足
标准残差连接只是简单的 out = x + f(x),信息通路单一。
mHC 通过 hc_pre 将输入映射到多路混合空间(hc_mult 路),在 hc_post 阶段用 post 和 comb 对当前层输出和残差做加权组合,相当于同时维护了多条残差通路,增强了表征能力。 - 原始 Hyper-Connections 深层训练崩溃
纯超连接在深层网络中容易出现数值不稳定或训练崩溃。
mHC 的核心创新是引入 Sinkhorn 归一化:将组合矩阵 comb 约束为双随机矩阵(每行、每列和均为 1)。
这保证了多路残差之间的信息流动是均衡且稳定的,避免了权重爆炸或消失,从而解决了深层训练崩溃问题。


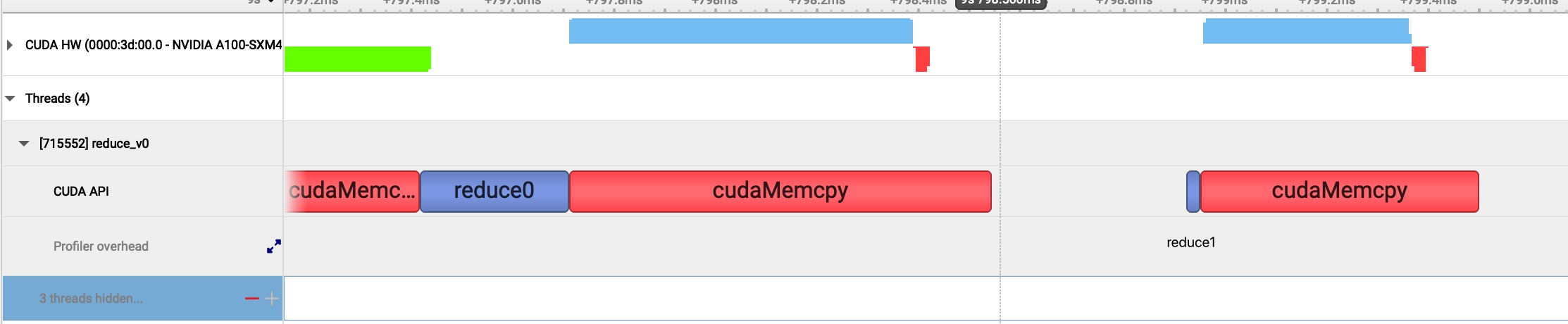 从上图可以看出 cuda hardware 的函数执行时间情况和 cpu 侧的执行时间情况。下面是核函数的发射时间,上面 device 侧是核函数实际执行时间,和 gpukernsum 统计的时间一致。
从上图可以看出 cuda hardware 的函数执行时间情况和 cpu 侧的执行时间情况。下面是核函数的发射时间,上面 device 侧是核函数实际执行时间,和 gpukernsum 统计的时间一致。 上图是在软件中可以看见的较为详细的统计数据,和命令行结果一致。
上图是在软件中可以看见的较为详细的统计数据,和命令行结果一致。