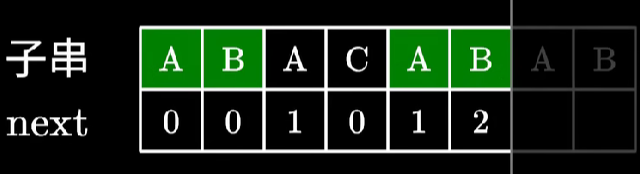
next 数组的本质是寻找子串中“相同前后缀的长度,并且最长”。并且不能是字符串本身。举个例子而言,如下所示:
A
B
A
B
C
0
0
1
2
0
第 1位 A 只有一个字符,不能是字符串本身,为 0;
第 2位 B 和 A 比较,不相等,为 0;
第 3位 A 和 A 比较,相等,所以相同前缀为 1;
第 4位 B 和前缀为 1 后的 B 比较,相等,和前缀组成了 AB 的相同模式的串,所以相同前缀为 2;
第 5 位 C 和前缀为 2 后的 A 比较,不相等,和前缀长度为 0 的比,相同前缀为0;
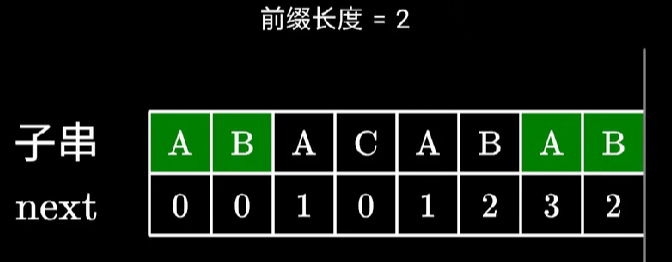
关于最长前缀的理解是,如下图所示。
最后一位的 A 很显然可以和 ABA 组成长度为 3 的相同前缀,也可以自己 A 组成长度为 1 的相同前缀。这种情况下选择较大的那个值。
求解next数组
next 数组求解的本质是动态规划。假设我们已经知道当前数字的共同前后缀了,如下图所示。
接下来求第 i 位的 next 数组,分为两种情况。
下一位也和前缀相等
那就很明显等于 next[i−1] 加上 1。
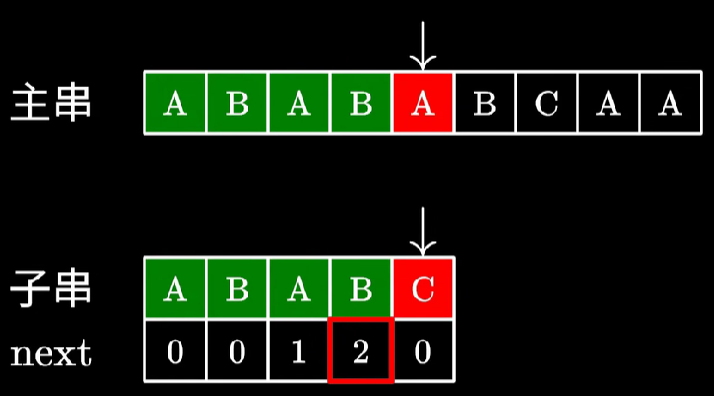
下一位和前缀不相等
这里不是直接等于 0 哦。如下图所示
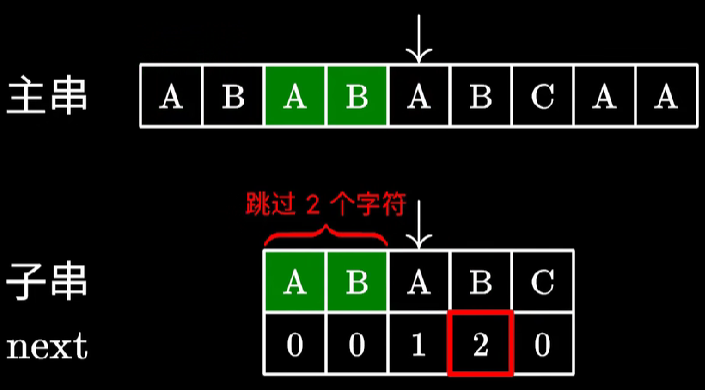
虽然 ABAB 和 ABAC 并不相等,但是也不能直接设为 0。因为这个新来的 B 可以和前面的 A 组成 AB,达到 2 的长度。那么这个数难道要暴力求解吗?其实不然。此时第 i−1 位的 next 的可利用的值在前缀的 next 数组中可以得到答案,在本图中为 next[2],即是 1。此时修改前缀长度为 next[2],则又回到了最开始的状况,匹配长度为 1 并且匹配下一位,下一位 B 相等,所以 next[i] 为 1+1=2。
代码如下: