推理性能优化
推理优化工作可以归成四类
- 算子优化
- 图优化
- 模型压缩
- 部署优化
算子优化
算子优化就是优化单算子的性能,方法无非是算法优化和微架构优化。
对同一个算子可能有不同的算法去实现它。举个例子,对卷积算法我们常见的就有:矩阵乘法,直接卷积法,Winograd 变换法,FFT 变换法。需要我们针对目标问题,分析并实现合适的算法,来达到最佳性能。
微架构优化。微架构优化主要焦点是如何充分利用好微架构的内置加速器的能力去最大化算子的性能。
图优化
图优化主要通过子图变换和算子融合的方式来达到减少计算量或者其他系统开销(如访存开销),从而达到性能优化的目的。图优化主要是希望在不影响模型的数值特性的基础上,通过图变换达到简化计算、资源开销,提升性能,所以是性能优化时的首选方法之一。
子图变换
子图变换主要是通过数学变换的手段对图进行精简,从而减少计算和调度开销。常见的有常数折叠,公共子表达式折叠以及算术变换。
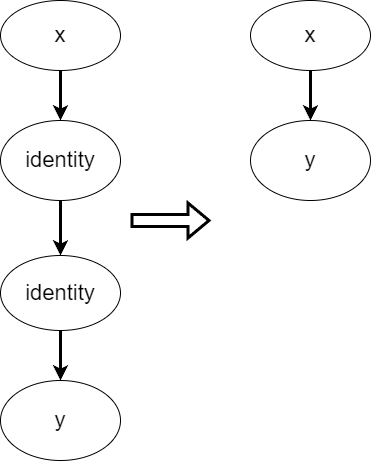
常数折叠 (Constant Folding)

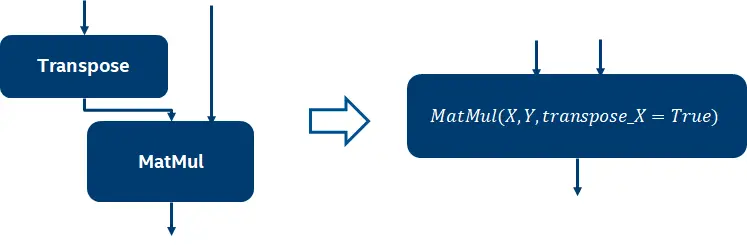
算数变换
算子融合
在深度学习中,一般来说,计算密集型和访存密集型算子是相伴出现的。这时候我们可以通过 fusion 来实现寄存器计算,从而减少访存密集型算子的访存,减少内存访问延时和带宽压力,提高推理效率。
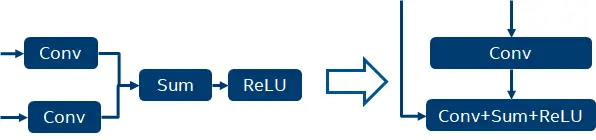
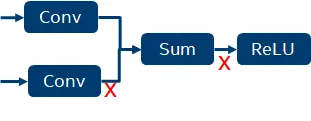
通过这种方式,减少两次 tensor 的内存读写操作。
模型压缩
上面的方案都是精度无损的,当这三点都做完了后,如果还需要额外的性能增益,这时候需要考虑模型压缩方案。
模型量化
模型量化主要是通过降低模型中 tensor 和 weights 精度的手段,从而减少计算需求和数据存储与传输需求,来达到加速的目的。例如把权重从 FP32 降低为 FP16。虽然可以加速,但是有一定的精度损失。
模型蒸馏
模型蒸馏采用的是迁移学习的方法,通过采用预先训练好的复杂模型(Teacher Model)的输出作为监督数据,去训练另外一个简单的网络(Student Model),最后把 Student Model 用于推理。有精度损失。
部署优化
部署优化主要通过调整模型在部署时的资源分配和调度的参数来进一步优化性能。如,调整了 NUMA 的参数。