硬件结构
现代机器都是多个处理器,每个处理器有自己的 cache。这个结构如下所示:
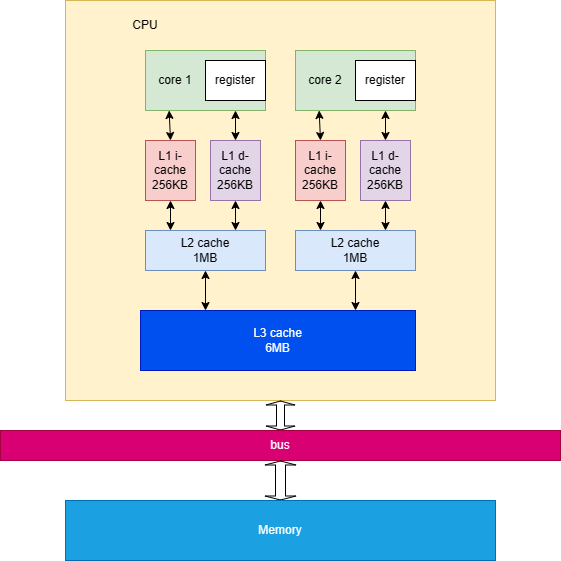
可以看到,每个 CPU 都有自己的缓存,之后再写到内存中。并且由于编译器的优化,你写的代码可能和你执行的代码顺序有所不同。他们优化的规则是:保证对于一个单核情况下,执行结果不会发生变化。但是多线程就不一定了。
那么在多线程情况下,如何协调这些 CPU 缓存的数据一致性就成了一个问题。
常见优化
再谈保证数据的一致性之前,先谈谈编译器能做的优化。
重排 Reordering
编译器和 CPU 都会发生重排,为了提升代码的效率。采用乱序执行、流水线、分支预测以及多级缓存等方法来提升程序性能。编译器会基于这些规则来提升自己代码的速度,所以就会对指令进行优化。例子如下:
1 | int a = 0; |
1 | @└────> # gcc 1.c -O0 -g |
- 对于 O0 等级的优化,执行顺序是 L5->L6。
- 但是对于 O2 等级的优化,执行顺序是 L6->L5,但是结果是不影响的。
为什么要这么做呢?因为 CPU 读取数据从 cache 中读取。如果不优化的话,先读 b,再读 a 的时候可能把 b 的缓存换出去了,那么再写 b 的时候还需要把 b 换进来。但是如果优化了,就是读 b,写 b,再写 a,就不存在缓存的换入换出了。
插入 Invention
假设有如下代码:
1 | for (int i = 0; i < n; ++i) { |
可能优化成如下:
1 | for (int i = 0; i < n; ++i) { |
预读取这些数据来减少缓存未命中次数。
删除 Removal
删除很好理解了,删除没用的变量赋值。
1 | int x = 1; |
优化后:
1 | int x; |
关系术语
sequence-before
sequence-before 是对一个线程内,求值顺序关系的描述:
- A sequence-before B,先对 A 求值,再对 B 求值。
- A not sequence-before B,并且 B not sequence-before A,那么 A 和 B 谁先求值是未知的。
synchronizes-with
描述的是不同线程内的执行关系。在两个线程分别执行时,即使线程 A 先执行,线程 B 后执行,A 中写了某个共享变量,由于指令重排或者写到了 cache 或寄存器没来得及写入内存导致 B 读到了错误的值。
- A synchronizes-with B,在线程 A 中的写操作结果对线程 B 可见。
happens-before
是 sequence-before 的扩展,包括了不同线程的关系。
- A happens-before B,那么不但 A 先于 B 执行,并且 A 的结果对 B 可见。
- 同线程:和 sequence-before 一样。
- 不同线程:和 synchronizes-with 一样。
内存序
C++11 中引入了 6 种内存序:
1 | typedef enum memory_order { |
| 内存序类型 | 用于读/写 | 含义 |
|---|---|---|
| memory_order_relaxed | 读/写 | 仅要求原子性和内存一致性 |
| memory_order_consume | 读 | 读操作所在线程该操作后面的和该变量 有依赖关系的 读写操作不会被优化到先于该操作执行 |
| memory_order_acquire | 读 | 读操作所在线程该操作后面的读写操作不会被优化到先于该操作执行 |
| memory_order_release | 写 | 写操作所在线程该操作前面的读写操作不会被优化到后于该操作执行 |
| memory_order_acq_rel | 读/写 | 是 memory_order_acquire 和 memory_order_release 组成的双向屏障,上下皆不能跨过该指令 |
| memory_order_seq_cst | 读/写 | 双向屏障,并且该线程所有原子指令并且也指定为 memory_order_seq_cst 的都已全局内存修改顺序为参照 |
值得一提的是,若一个原子变量在一个线程中施加了 memory_order_release,但是在其他线程中没有使用 memory_order_acquire 或 memory_order_consume 读取,那么他就不会具备 memory_order_release 所赋予的屏障功能。(即只有被观测才会起作用,读操作也是如此)
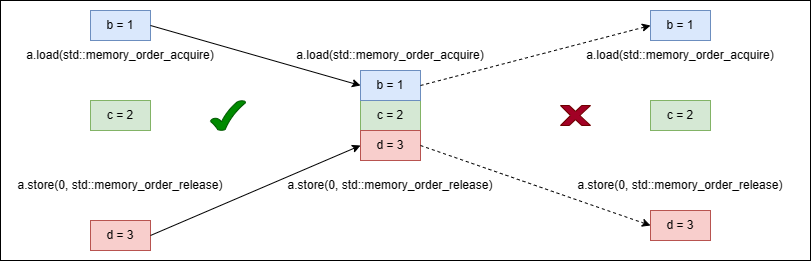
如上图所示,就像加锁一样会构成临界区。但是外面的变量可以移入临界区,却不能移出去,所以称 memory_order_acquire 和 memory_order_release 如同单向屏障一般。
内存模型
一言以蔽之,引入内存模型的原因,有以下几个原因:
- 编译器优化:在某些情况下,即使是简单的语句,也不能保证是原子操作。
- CPU out-of-order:CPU 为了提升计算性能,可能会调整指令的执行顺序。
- CPU Cache 不一致:在 CPU Cache 的影响下,在某个 CPU 下执行了指令,不会立即被其它 CPU 所看到。
从上面的内存序中,按照访问控制的角度可以分为三种模型:
- Sequential Consistency 模型
- Acquire-Release 模型
- Relax 模型
其中,Sequential Consistency 模型约束最强,Acquire-Release 次之,Relax 模型最弱。
Sequential Consistency 模型
对应 memory_order_seq_cst 内存序。Sequential Consistency 模型有以下特点:
- 每个线程的执行顺序与代码顺序严格一致
- 线程的执行顺序可能会交替进行,但是从单个线程的角度来看,仍然是顺序执行
例如:
1 | x = y = 0; |
那么可能的执行顺序为:
| 可能性 | 第一步 | 第二步 | 第三步 | 第四步 |
|---|---|---|---|---|
| 1 | x = 1 | r1 = y | y = 1 | r2 = x |
| 2 | y = 1 | r2 = x | x = 1 | r1 = y |
| 3 | x = 1 | y = 1 | r1 = y | r2 = x |
| 4 | x = 1 | r2 = x | y = 1 | r1 = y |
| 5 | y = 1 | x = 1 | r1 = y | r2 = x |
| 6 | y = 1 | x = 1 | r2 = x | r1 = y |
std::atomic 默认值都是使用 memory_order_seq_cst,保证不出错。但是相对的,限制了 CPU 并行处理的能力,会降低效率。这个模型的所有线程都参考全局的内存修改顺序。因此,我们可认为所有变量的读写都直接从内存进行,从而完全不用考虑 Cache,Store Buffer 这些因素。
Acquire-Release 模型
对应 memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel 内存序。对于一个原子变量 A,对 A 的写操作(Release)和读操作(Acquire)之间进行同步,并建立排序约束关系,即对于写操作(release)X,在写操作 X 之前的所有读写指令都不能放到写操作 X 之后;对于读操作(acquire)Y,在读操作 Y 之后的所有读写指令都不能放到读操作 Y 之前。
Relax 模型
对应的是 memory_order_relaxed 内存序。其对于内存序的限制最小,也就是说这种方式只能保证当前的数据访问是原子操作(不会被其他线程的操作打断),但是对内存访问顺序没有任何约束,也就是说对不同的数据的读写可能会被重新排序。