模型打印
已Llama-7B hugging face版本为例:
1
2
3
4
5
6
| import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = torch.device("cuda:{}".format(gpu))
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code = True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code = True).half().to(device)
print(model)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
|
从结构可以看出来,模型参数量为 32,000∗4,096+32∗(4,096∗4,096∗4+4,096∗11,008∗3)+4,096∗32,000=6,738,149,376。所以约为7B。
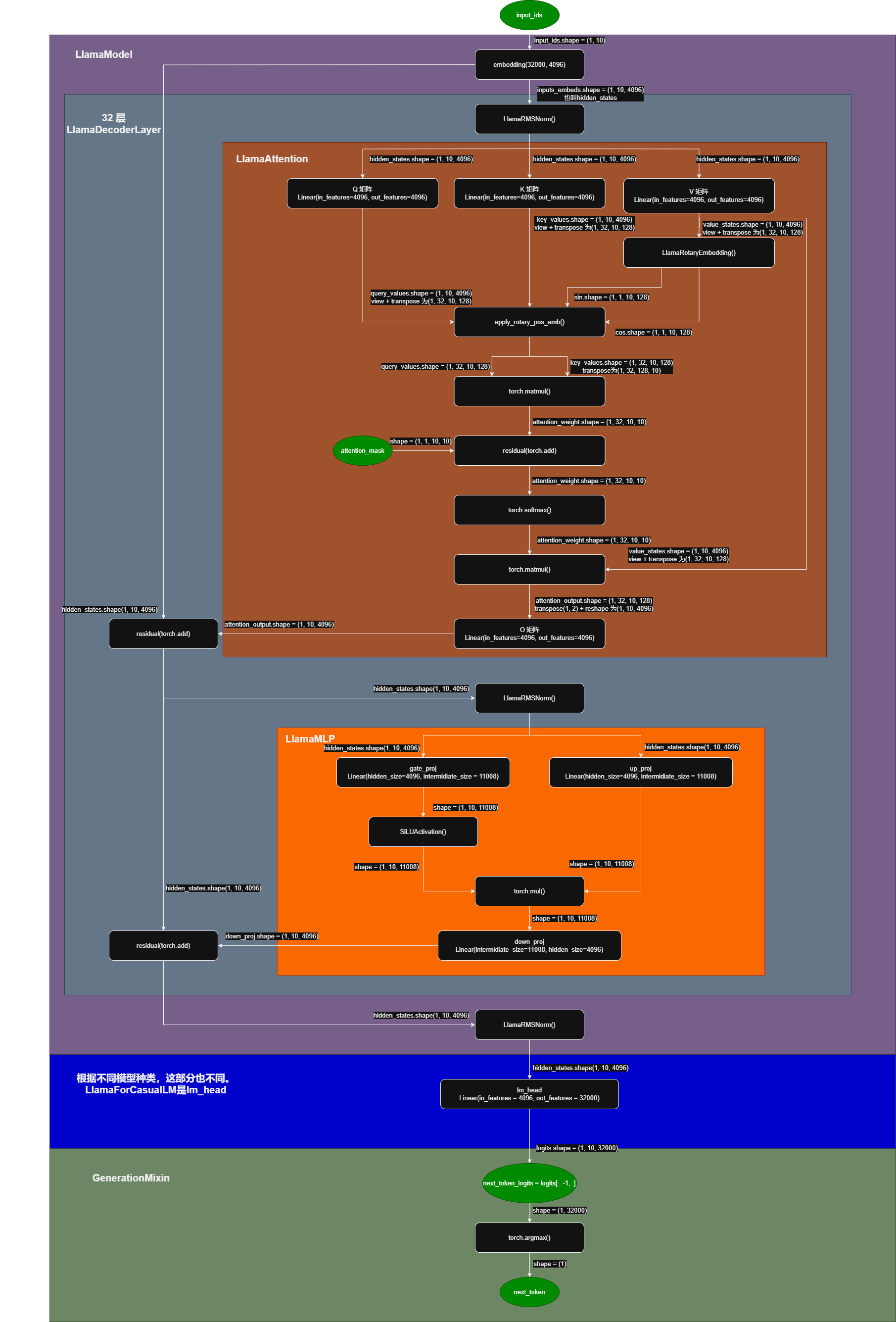
模型图解
以输入为 10 个 token 为例: