AWQ Activation-aware Weight Quantization(感知激活的权重量化)
该量化方式为 MIT 韩松团队 2023 年提出的大模型训练后 (PTQ Post Training Quantization)量化方案,核心方法是通过激活值分布识别重要的权重通道,用数学缩放来减小量化误差。
背景
AWQ 的设计基于两个重要的实验发现:
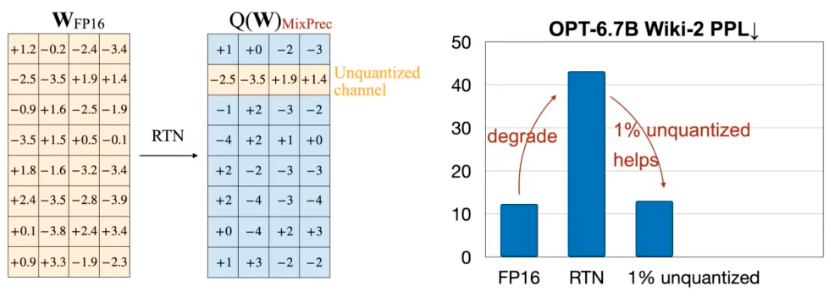
- 权重重要性并非对等的,而是不均衡的:大模型中只有 0.1% - 1% 的显著权重通道对于模型的精度有决定性作用。这部分权重如果被扰动,会造成极大的精度损失。而其他的权重对结果影响很小。他们在权重量化时,保留了部分重要权重使得该部分保持原来的精度,而其他的权重进行量化,模型的推理结果精度误差很小。

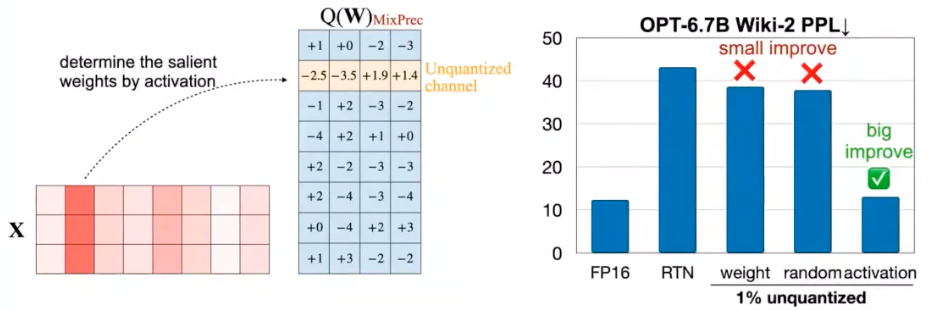
- 权重的重要性由激活值决定:基于权重绝对值大小而挑选出的重要权重效果极差(说明并不是这么个重要法),而基于输入激活值的分布(激活能量)来识别重要的重要权重,能实现近乎无损的量化。原因是激活值越高的权重通道,量化的误差会在矩阵乘法中被持续放大,对模型的影响更高。
对于第 j 个输入通道的 N 个元素,激活能量 sX,j 的官方标准公式:
sX,j=E[X2]=N1i=1∑Nxi,j2
为什么用均方值 E[X²]?
AWQ 论文对比了多种统计量,最终确定 均方值(二阶矩) 效果最优,原因如下:
| 统计量 |
缺陷 |
均方值的优势 |
| 均值(E[x]) |
正负激活值会相互抵消,无法反映真实幅值 |
平方后消除符号影响,精准体现激活幅值 |
| 绝对值均值(L1) |
对高幅值异常值不敏感,无法匹配误差放大规律 |
平方操作会放大高幅值激活的权重,完美贴合量化误差的平方级传播特性 |
| 最大值 |
单样本极值会导致统计结果不稳定,泛化性差 |
基于全量校准集取平均,统计结果稳定,适配任务分布 |
但是对于保留部分权重原来精度的方式,系统设计上实现很复杂。需要修改整个结构,还要设计对应的 kernel。于是他们提出,可以通过放大重要权重,与此同时缩小激活值,可以达到相同的效果。
量化步骤
公式
下面的公式时对称量化的核心公式:
Q(w)=Δ⋅round(Δw),Δ=2N−1max(∣w∣).
Q(w)⋅x=Δ⋅Round(Δw)⋅x
其中,W 是量化前的 fp16 权重,Δ 是基础量化步长(缩放因子)。N 是量化比特数。
而 AWQ 量化算法,则是在原版基础上,加了个 sclae 缩放参数,对权重进行了进一步缩放。AWQ 的公式:
Q(w⋅s)⋅sx=Δ′⋅Round(Δ′w⋅s)⋅x⋅s1
为什么量化误差会减小?
对于这两种算法,量化误差为:
Q(w)⋅x=Δ⋅Round(Δw)⋅xQ(w⋅s)⋅sx=Δ′⋅Round(Δ′w⋅s)⋅x⋅s1Err(Q(w)⋅x)=Δ⋅Err(Round(Δw))⋅xErr(Q(w⋅s)⋅sx)=Δ′⋅Err(Round(Δ′w⋅s))⋅x⋅s1
其中,W 是量化前的 fp16 权重,Δ 是基础量化步长,Δ′ 是缩放权重后的量化步长,N 是量化比特数。
可以看到在这两个公式中,对于 Round 而言,他是舍入误差,误差是常数。对于量化前和量化后的步长而言,如果 s 不是特别大的话,那么Δ≈Δ′。所以 AWQ 的量化误差是原版的 1/s。
那么为什么不是 s 越大越好?
因为我们之前假设 Δ≈Δ′。如果 s 过大,那么 Δ′≈Δ 的假设就不成立了,则由 Δ′ 引起的量化误差就会增大。
如何获取合适的 s 值?
L(s)=∥∥∥Q(W⋅s)(s−1⋅X)−WX∥∥∥
s=sXα,α∗=argαminL(sXα)
找到能让损失函数最小的 α 值,通过网格搜索来解决。其中,sX 是上面提到的激活能量。
AWQ 的 α 网格搜索是逐层独立执行的(Transformer 的每个 Linear 层单独搜索最优 α,不同层的激活分布差异大,独立搜索精度更高)。
寻找流程如下:
-
搜索前的固定准备(不可动态调整)
在启动网格搜索前,必须先固定所有影响量化结果的配置。量化比特数(如 4bit)、分组大小(group_size,主流 128)、量化类型(对称 / 非对称)、截断策略,这些参数会直接影响量化误差,搜索全程保持不变。
-
准备校准数据集:选取 128-512 条与目标任务分布一致的短文本样本(如通用对话、代码),数据量远小于 QAT/GPTQ,且无需标注,仅用于前向传播、统计激活分布。
-
逐通道计算固定激活统计量 sX:将校准数据输入模型,对目标 Linear 层执行前向传播,逐输入通道统计激活能量 sX,得到固定的sX向量,全程不再更新。
-
设定 α 的搜索区间:α∈[0,1]。
α=0,s=1,无任何通道缩放,退化为普通就近舍入量化,作为精度基线;
α=1:缩放强度最大,s 与激活能量完全成正比,高激活通道被最大程度放大保护;
区间外的 α(如 > 1)会导致非显著通道的量化噪声被过度放大,整体误差不降反升,因此无需搜索。
-
网格搜索:
标准配置为 20 个网格点,对应步长 0.05,即 α 候选值为:0, 0.05, 0.10, 0.15, …, 0.95, 1.00。
工程上可根据需求调整:点数越多,精度上限越高,但搜索耗时线性增加;20 个点是精度与效率的最优平衡。
-
最优 α 的选择与落地
遍历完所有 α 候选值后,选择损失值最小的 α,作为当前层的最优 α;
用最优 α 重新计算最终的通道缩放因子 s=sXα,对权重执行正式的预缩放、量化、存储,完成该层的 AWQ 量化;
对 Transformer 的所有 Linear 层,重复上述完整流程,完成整个模型的量化。