大模型Attention发展历程
MHA Multi Head Attention
MHA 相比于传统的 Self-Attention 提升了模型的表达能力。例如一个专家组对比一个专家。
先看代码:
1 | def forward( |
这个 attention 是 Multi-head self-attention,注意力有头这个概念。其中,Q K V 这三个向量分别是由 hidden_states 乘上一个 Linear 层来计算的。这里面由于是多头注意力机制,所以需要让 Q K V 的 shape 变为 (batch, seq_len, num_head, head_dim)。之后 transpose 成 (batch, num_head, seq_len, head_dim),这么做的目的是为了让后续计算时,每个头可以独立进行注意力计算,让 num_head 变为“批次”的一部分,注意力仅在 seq_len 维度计算,而不把不同的 head 混在一起算。
再算完这几个向量后,需要对 Q K 向量添加位置信息,这就是 apply_rotary_pos_emb 的作用。之后就是 attention 的计算,也就是我们说的公式:
其中,QK 的意思是 Q 和 K 的点积,表示 Q 和 K 之间的相似性,更进一步,这个向量是词向量,是词在高维空间的数值映射。词向量之间相关度高表示什么?是不是在一定程度上(不是完全)表示,在关注词 A 的时候,应当给予词 B 更多的关注?除以 的作用是训练时防止梯度消失。
算完 attention 后,再被 o_projection 映射,结果就算出来了。
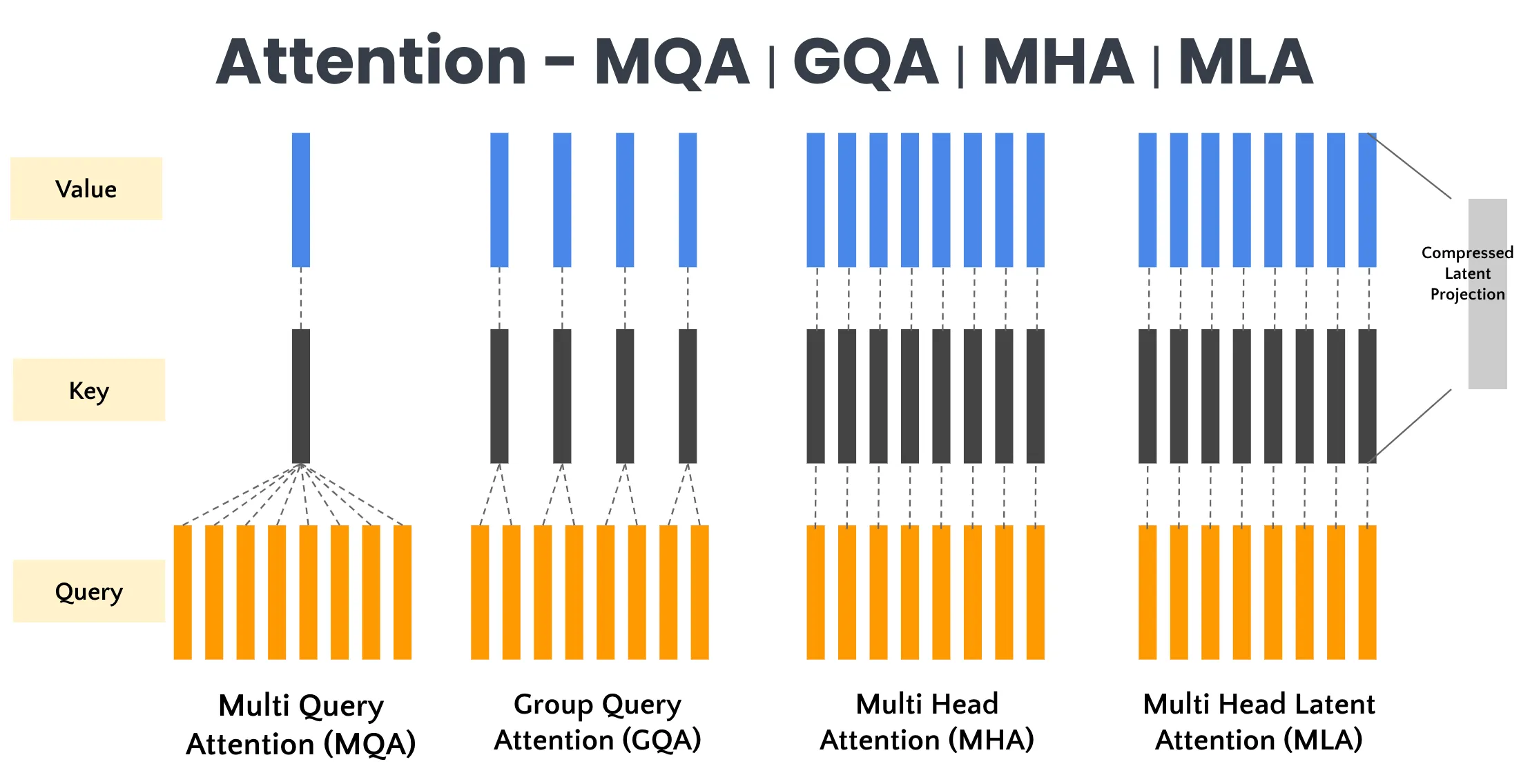
- MHA (Multi-Head Attention):假设头个数为32,
- 配置:每个 Query 头都有自己独立的 Key 头和 Value 头。
- 数量:32 个 Q 头,对应 32 个 K 头 和 32 个 V 头。
- 特点:完全独立,信息隔离性好,模型表达能力强。
总结:MHA 多头自注意力机制是效果最好的也是最慢的,而 MQA 和 GQA 则是通过不同的方式来提升计算效率。
一些比较出名的模型,如 LLama2-7B、LLama2-13B 使用的都是这种架构。
MQA Multi Query Attention
相比 MHA,MQA 允许一个 Query 头同时关注多个 Key 头和 Value 头,从而在保证信息隔离性的前提下,提升模型的计算效率。
- MQA (Multi-Query Attention):假设头个数为32,
- 配置:所有的 Query 头共享同一组 Key 和 Value 头。
- 数量:32 个 Q 头,对应 1 个 K 头 和 1 个 V 头。
- 特点:极端压缩,推理速度极快,但模型效果下降明显(因为所有头被迫看同样的 K/V 信息)。
目前没听说哪个模型全程使用这个架构。但是 DeepSeek V3.2 的 decode 阶段使用了该方式。
GQA Group Query Attention
GQA 相比 MHA,其主要区别在于,GQA 是先进行“组内”注意力计算,再进行“组间”注意力计算。也就是说,GQA 首先将 Q K V 分成多组,然后在组内进行注意力计算,最后在组间进行注意力计算。推理速度更快,普遍用于 70B 及更大的模型中。MHA 则用于稍微小一点的模型中。
1 | def forward( |
可以看见代码里有一个 repeat_kv 的操作,作用是将较少的 Key/Value 头复制扩展,使它们能和 Query 的头数一一对应进行矩阵乘法。这正是 GQA 的典型操作:“分组共享,通过复制来对齐”。
- GQA (Grouped Query Attention):
- 配置:将 Query 头分组,每组 Query 头共享一组 Key 和 Value。
- 数量:例如分为 8 组(Group=8)。32 个 Q 头,对应 8 个 K 头 和 8 个 V 头(每4个Q头共享1个K/V头)。
- 特点:介于 MHA 和 MQA 之间。比 MQA 效果好(保留了部分独立性),比 MHA 速度快(KV Cache 大小减少了 4 倍)。
GQA 相比于 MHA,效果上几乎相近,而速度却能达到 MQA 的水平,被广泛的应用在现在的大模型上。
LLama2-70B、LLama3、Qwen2 全系列使用的都是这种架构。
MLA Multi Latent Attention

1 | def forward( |
上面代码是 MLA 的流程。可以分为以下几步:
- Query 的生成与压缩
DeepSeek 对 Q 进行了压缩,减少计算量
1 | # 这一部分对应 Query 的生成 |
- KV 的压缩与潜在向量生成
1 | # 【核心 MLA 特征】:KV 压缩 |
- KV 的解压与还原
1 | # 1. 对压缩的内容特征进行 LayerNorm |
虽然我们在 Cache 里存的是压缩后的向量,但在计算当前时刻的 Attention 分数时,需要将其还原成完整的多头 Key 和 Value。虽然计算量增加了一些,但换来了显存带宽的大幅节省。
- 位置编码与拼接
1 | # 对专门的位置部分应用 RoPE |
最终参与计算的 query_states 和 key_states 是由“非旋转部分”和“旋转部分”拼接而成的。这样做的好处是,位置信息不会破坏压缩向量的低秩结构。为什么位置编码要这么做呢?因为在实现 MLA 的时候,有一个小技巧叫做“矩阵吸收”。
在这个公式中,可以将 kv 的上投影矩阵看成是,这样子,位置信息部分就可以通过矩阵吸收的方式,被“吸收”进去了。但是如果加了常规旋转位置编码的话,位置信息部分就无法被“吸收”进去了。可以看见被隔断了。无法吸收,会导致推理效率下降。
所以引入了 Decoupled RoPE (解耦 RoPE)。q_rot 和 k_rot 分开处理,这样位置编码和内容编码就可以分开处理,互不干扰。
- 注意力计算
1 | # 更新 KV Cache (这里存储的通常是还原后的 K 和 V,或者是压缩向量,取决于具体的 Cache 实现) |
- MLA (Multi-Head Latent Attention)
- 配置:通过生成 compressed_kv,将 KV Cache 的大小压缩了 90% 以上。存储上 compressed_kv 只有一份,接近 MQA。
- 数量:通过 kv_b_proj 动态还原 KV,保留了多头注意力的表达能力。每个头一个 KV 数量,这一部分接近 MHA。
- 特点:通过 split 和 cat 操作,把位置信息和内容信息分开处理,使得压缩机制能与 RoPE 完美兼容。
NSA Natural Sparse Attention
该注意力机制首次被提出是在 2025 年的 2 月。由 DeepSeek 针对长序列处理提出的原生稀疏注意力机制,属于 block-wise 的稀疏方案。这个目前只存在于论文中,没有实际用于某个模型。直到 Deepseek-V3.2 中,他们提出了 DSA,可以说是 NSA 的一个变种实现, 属于 token-wise 的稀疏方案。
- 压缩块,计算块间注意力
标准自注意力需要计算序列中每个词元(Token)与其他所有词元的关系。对于一个长度为 N 的序列,需要计算 N*N 个注意力权重,随长度二次增长。
解决方案是,NSA 不再以单个 token 为基本计算单元,而是将连续的多个 token 聚合成一个 block。例如,将 4096 个词元的序列划分为 64 个块,每个块包含 64 个 token。
计算流程转变:
之前(标准注意力): 处理 4096 个 token -> 需要处理 4096 * 4096≈16.7M 个关系对。
之后(块压缩): 处理 64 个 block -> 先计算块与块之间的注意力。此时,需要处理的关系对数量骤降至 64 * 64=4096 个。 - 重要性筛选:选出重要的 K 个块
在压缩后的 block 中,筛选出需要详细看的部分:
块压缩是假设所有 block 都同等重要。但实际上,对于当前要处理的 token 来说,某些 block 是关键的而其他的是次要的。NSA 引入动态机制,根据当前的 Q 内容,评估并筛选出最相关的少量关键 block。
系统会为每个 block 计算一个“重要性分数”。这个分数通常基于当前 Q 与每个 block 的“摘要向量”(通常是 block 内 token 的均值或通过一个小型网络生成)的相似度。
在块压缩的基础上增加重要性筛选,系统从64个块中选出最相关的 K 个块(例如 K=8),额外计算当前查询向量与这 K 个关键块内全部 token 的注意力。 - 滑动窗口
为了保证局部上下文信息的完整性,token 不但要关注遥远的关键块,还要关注紧挨着它的其他 token。NSA 强制性地规定,无论重要性筛选的结果如何,每个 token 都必须关注以其自身为中心的一个局部窗口内的所有其他token。这个窗口是“滑动”的,因为它随着 token 位置的变化而移动。例如,假设滑动窗口大小为 256。那么对于序列中第 500 个 token,无论如何它都会关注第 500-255 至第 500 这个范围内的所有 token。
DSA DeepSeek Sparse Attention
DSA 首次被应用在 Deepseek V3.2 Exp 中,属于 token-wise 的稀疏方案。DeepSeek-V3.2-Exp 仅在 DeepSeek-V3 的基础上新增了 Lightning Indexer 模块,用于选择参与 attention 的 token。
该模块的主要输入是 compressed_q 与 MLA 的输入矩阵 hidden_states,输出则是每个 token 所对应的 2048 个可参与 attention 计算的历史 token 的 index。
被选中的 2048 个 token 会在 attention 的 mask 阶段发挥作用:通过将未选中的位置的 mask 值设为 inf,在经过 softmax 之后,就能有效去除不需要参与 attention 的 token。这样实现了高效的稀疏化,显著降低了计算量。从O(L^2)降到了O(LK),其中 K<<L 为 2048。
Indexer 代码(来自于官方 DeepSeek V3.2 仓库):
1 | def fp8_index( |
公式如下:
总体框架如下:

其中,绿色部分是 indexer 实现。而框住的部分是函数 fp8_index 部分。可以看到,虽然说 attention 的计算复杂度降低了,但是实际上选择不同 token 重要性这个 indexer 模块,也算是个 attention。还是需要计算查询相对于之前每个 token 的 attention 的重要性分数,复杂度还是 。只不过这个过程是在 fp8 精度下进行的,所以效率会比较高。
为什么需要哈达玛变换"rotate_activation"?
直接量化 q 和 k 向量可能会造成精度损失。引入旋转变换操作:将大范围数值打散到小范围。可以与随机的正交矩阵相乘来做这件事,使得向量数值分布均匀且模长不变。不过矩阵乘法代价较大。于是使用小代价的哈达玛变换。
最后得出的topk_indices,会作为 mask 输入到 MLA 中,从而实现稀疏化。可以看下面代码。
对于 Deepseek V3.2 的 attention 实现而言:
1 | def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]): |