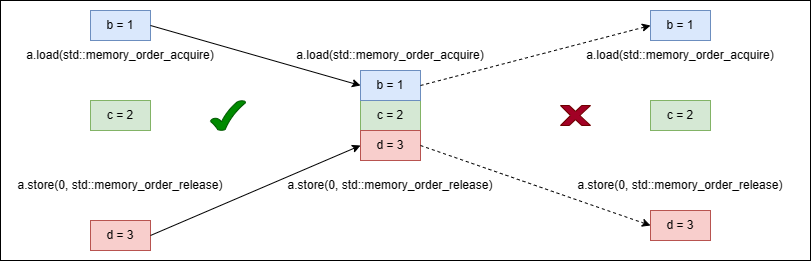
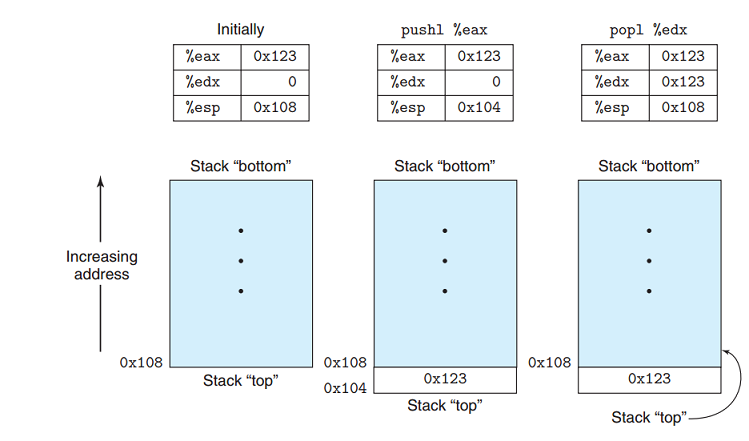
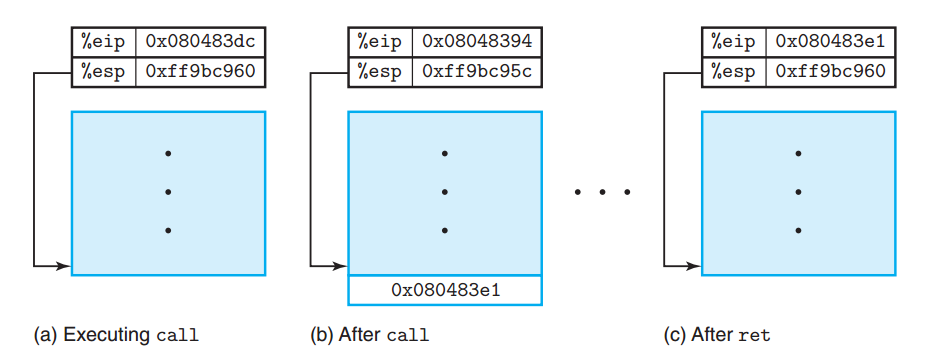
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
@└────>
@└────>
...
[4/8] Executing 'osrtsum' stats report
Time (%) Total Time (ns) Num Calls Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- ------------- ------------- --------- ------------- ------------- ----------------------
49.8 6,560,704,940 41 160,017,193.7 100,127,248.0 2,946 3,656,490,088 561,147,066.6 poll
40.5 5,331,726,596 1,591 3,351,179.5 34,054.0 1,200 405,442,288 30,016,785.5 ioctl
4.7 614,593,088 60 10,243,218.1 10,295,123.0 1,532,148 14,425,405 2,880,533.4 waitpid
2.6 341,072,143 60 5,684,535.7 5,470,557.0 576,832 10,285,481 1,599,344.7 fork
2.4 312,589,312 113 2,766,277.1 14,265.0 4,724 267,144,344 25,109,089.4 open64
0.0 5,684,320 144 39,474.4 11,704.5 1,108 3,826,795 317,952.4 fopen
0.0 2,034,643 38 53,543.2 10,234.5 3,945 1,236,239 198,417.6 mmap64
0.0 607,662 10 60,766.2 56,248.0 42,036 112,182 19,745.1 sem_timedwait
0.0 405,925 123 3,300.2 2,289.0 1,006 77,642 7,014.0 fclose
0.0 391,343 4 97,835.8 80,675.0 58,047 171,946 53,486.5 pthread_create
0.0 154,726 19 8,143.5 4,985.0 1,004 47,713 10,904.9 mmap
0.0 82,936 1 82,936.0 82,936.0 82,936 82,936 0.0 pthread_cond_wait
0.0 78,328 8 9,791.0 4,877.5 2,074 40,677 12,827.6 munmap
0.0 71,358 7 10,194.0 9,879.0 3,968 14,551 3,520.2 open
0.0 51,719 3 17,239.7 13,793.0 3,372 34,554 15,874.2 fread
0.0 42,644 29 1,470.5 1,295.0 1,000 5,372 801.5 fcntl
0.0 41,205 1 41,205.0 41,205.0 41,205 41,205 0.0 fgets
0.0 36,755 15 2,450.3 2,072.0 1,083 7,000 1,497.0 read
0.0 33,701 12 2,808.4 2,360.0 1,384 6,014 1,224.1 write
0.0 30,013 3 10,004.3 11,976.0 5,640 12,397 3,785.5 pipe2
0.0 26,410 2 13,205.0 13,205.0 10,057 16,353 4,451.9 socket
0.0 12,546 2 6,273.0 6,273.0 5,777 6,769 701.4 fwrite
0.0 10,654 2 5,327.0 5,327.0 4,160 6,494 1,650.4 pthread_cond_broadcast
0.0 10,412 1 10,412.0 10,412.0 10,412 10,412 0.0 pthread_mutex_trylock
0.0 9,158 1 9,158.0 9,158.0 9,158 9,158 0.0 connect
0.0 5,650 1 5,650.0 5,650.0 5,650 5,650 0.0 bind
0.0 3,085 1 3,085.0 3,085.0 3,085 3,085 0.0 listen
[5/8] Executing 'cudaapisum' stats report
Time (%) Total Time (ns) Num Calls Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- ------------- ------------- ----------- ------------- ------------- ----------------------
77.1 1,961,601,754 2 980,800,877.0 980,800,877.0 674,626,715 1,286,975,039 432,995,652.3 cudaMalloc
22.2 564,147,432 2 282,073,716.0 282,073,716.0 275,230,367 288,917,065 9,677,957.0 cudaFree
0.7 17,105,648 3 5,701,882.7 657,298.0 434,348 16,014,002 8,931,253.0 cudaMemcpy
0.0 415,480 2 207,740.0 207,740.0 42,497 372,983 233,688.9 cudaLaunchKernel
0.0 1,368 1 1,368.0 1,368.0 1,368 1,368 0.0 cuModuleGetLoadingMode
[6/8] Executing 'gpukernsum' stats report
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) GridXYZ BlockXYZ Name
-------- --------------- --------- --------- --------- -------- -------- ----------- ---------------- -------------- -------------------------
62.5 556,575 1 556,575.0 556,575.0 556,575 556,575 0.0 131072 1 1 256 1 1 reduce0(float *, float *)
37.5 334,111 1 334,111.0 334,111.0 334,111 334,111 0.0 131072 1 1 256 1 1 reduce1(float *, float *)
[7/8] Executing 'gpumemtimesum' stats report
Time (%) Total Time (ns) Count Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Operation
-------- --------------- ----- ------------ ------------ ---------- ---------- ----------- ------------------
99.7 15,820,690 1 15,820,690.0 15,820,690.0 15,820,690 15,820,690 0.0 [CUDA memcpy HtoD]
0.3 46,176 2 23,088.0 23,088.0 23,040 23,136 67.9 [CUDA memcpy DtoH]
[8/8] Executing 'gpumemsizesum' stats report
Total (MB) Count Avg (MB) Med (MB) Min (MB) Max (MB) StdDev (MB) Operation
---------- ----- -------- -------- -------- -------- ----------- ------------------
134.218 1 134.218 134.218 134.218 134.218 0.000 [CUDA memcpy HtoD]
1.049 2 0.524 0.524 0.524 0.524 0.000 [CUDA memcpy DtoH]
|
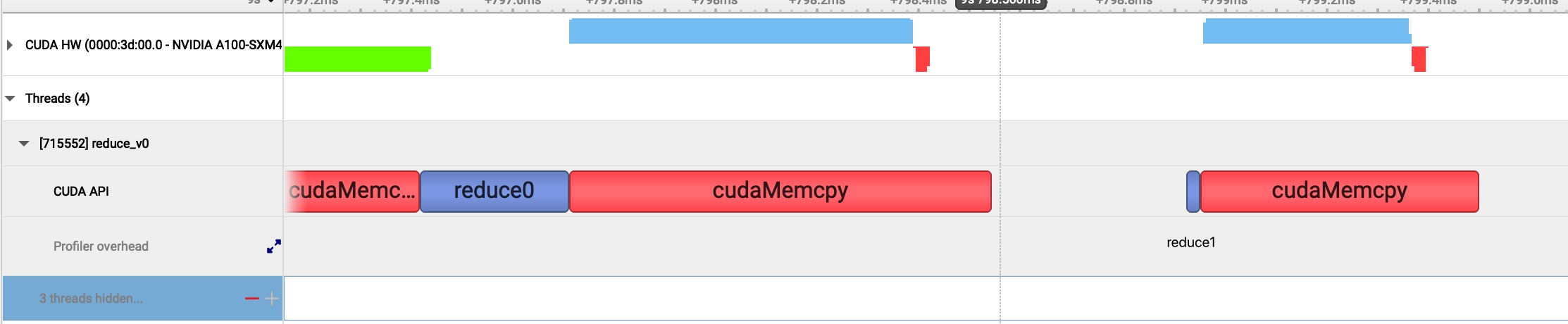 从上图可以看出 cuda hardware 的函数执行时间情况和 cpu 侧的执行时间情况。下面是核函数的发射时间,上面 device 侧是核函数实际执行时间,和 gpukernsum 统计的时间一致。
从上图可以看出 cuda hardware 的函数执行时间情况和 cpu 侧的执行时间情况。下面是核函数的发射时间,上面 device 侧是核函数实际执行时间,和 gpukernsum 统计的时间一致。 上图是在软件中可以看见的较为详细的统计数据,和命令行结果一致。
上图是在软件中可以看见的较为详细的统计数据,和命令行结果一致。