什么是多路复用
操作系统在处理 I/O 的时候,分为两个阶段:
- 等待数据到达内核空间。
- 等待数据从内核空间拷贝到用户空间。
在 Linux 操作系统中,多路复用的方式有三种。分别是 select,poll,和 epoll。I/O 多路复用为,只通过一种机制,可以监视多个描述符,一旦某个描述符就绪(读就绪/写就绪),能够通知程序进行相应的读写操作。
但 select,poll,epoll 本质上都是同步 I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步 I/O 则无需自己负责进行读写,异步 I/O 的实现会负责把数据从内核拷贝到用户空间。
select
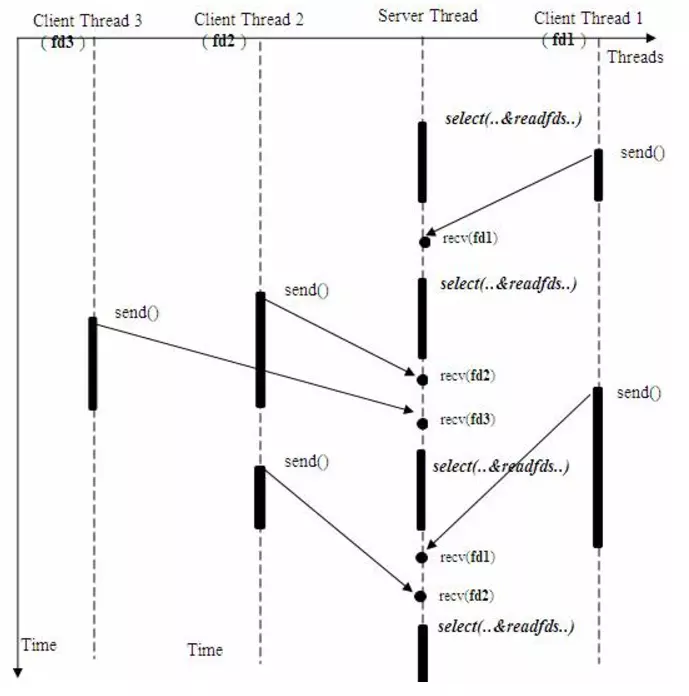
单个进程就可以同时处理多个网络连接的 I/O 请求(同时阻塞多个 I/O 操作)。
基本原理就是:
- 程序调用 select,然后整个程序就阻塞状态。
- 这时候,内核就会轮询检查所有 select 负责的文件描述符集合 fd_set(一般上限为 1024 个),当找到其中那个的数据准备好了的文件描述符返回给 select。
- select 进行系统调用,将数据从内核复制到进程缓冲区(用户空间)。
select的缺点:
- 每次调用 select,都需要把 fd_set 从用户态拷贝到内核态,这个开销在 fd 很多时会很大。
- 同时每次调用 select 都需要在内核遍历传递进来的所有 fd,这个开销在 fd 很多时也很大
- select 支持的文件描述符数量太小了,默认是 1024
poll
poll的原理与select非常相似,差别如下:
- 描述fd集合的方式不同,poll 使用 pollfd 结构而不是 fd_set 结构,是链式的,所以没有最大连接数的限制。
- poll 有一个特点是水平触发,也就是通知程序 fd 就绪后,这次没有被处理,那么下次 poll 的时候会再次通知同样的 fd 已经就绪。
poll 解决了 fd_set 有上限的情况,并且每次读就绪描述符集合时不用保存之前的状态。
epoll
epoll 提供了三个函数:
1 | int epoll_create(int size); |
epoll解决的问题:
- epoll没有fd数量限制
epoll没有这个限制,我们知道每个 epoll 监听一个 fd,所以最大数量与能打开的 fd 数量有关,一个 G 的内存的机器上,能打开10万个左右
- epoll 不需要每次都从用户空间将 fd_set 复制到内核
epoll 在用 epoll_ctl 函数进行事件注册的时候,已经将 fd 复制到内核中,所以不需要每次都重新复制一次
- select 和 poll 都是主动轮询机制,需要遍历每一个人 fd;而 epoll 是被动触发方式。
epoll_ctl 给 fd 注册了相应事件的时候,我们为每一个 fd 指定了一个回调函数,当数据准备好之后,就会把就绪的 fd 加入一个就绪的队列中,epoll_wait 的工作方式实际上就是在这个就绪队列中查看有没有就绪的 fd,如果有,就唤醒就绪队列上的等待者,然后调用回调函数。
虽然 epoll, poll, select 都需要查看是否有 fd 就绪,但是 epoll 之所以是被动触发,就在于它只要去查找就绪队列中有没有 fd,就绪的 fd 是主动加到队列中,epoll 不需要一个个轮询确认。
换一句话讲,就是 select 和 poll 只能通知有 fd 已经就绪了,但不能知道究竟是哪个 fd 就绪,所以 select 和 poll 就要去主动轮询一遍所有监听的 fd 才能找到就绪的 fd。而 epoll 则是不但可以知道有 fd 可以就绪,而且还具体可以知道就绪 fd 的编号,所以直接找到就可以,不用轮询。
注意,epoll 只有 Linux 上面有。