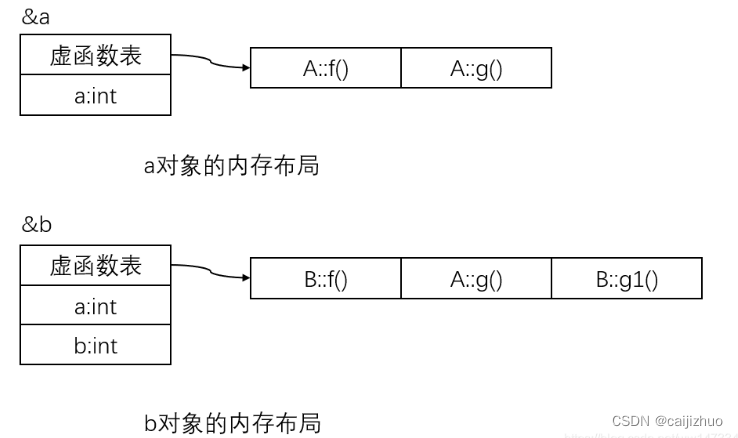
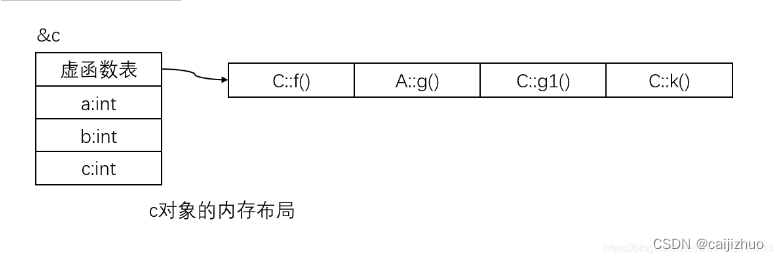
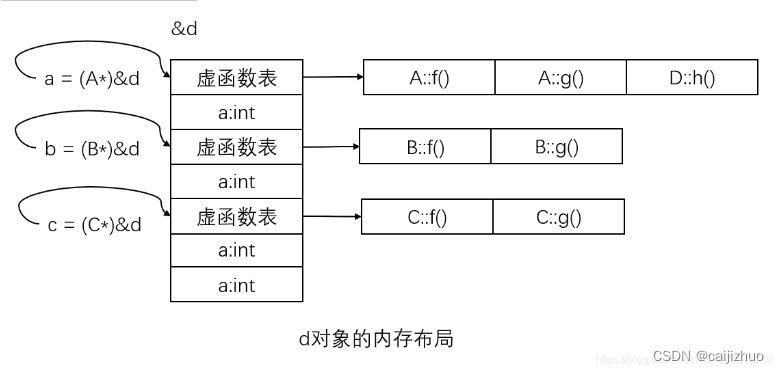
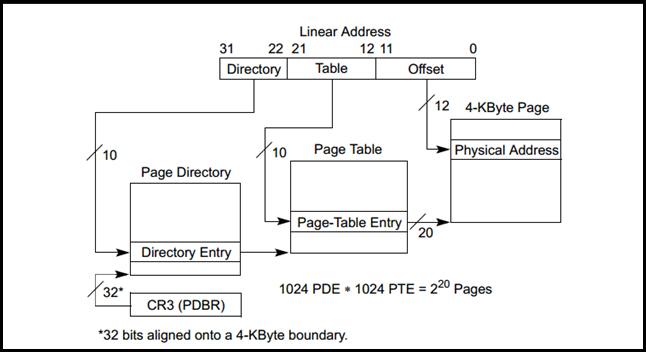
$ gdb a.exe GNU gdb(GDB) 7.6.1 Copyright(C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "mingw32". For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>... Reading symbols from F:\zkangHUST\C++\a.exe...done. (gdb) start Temporary breakpoint 1 at 0x40146e: file test3.cpp, line 32. Starting program: F:\zkangHUST\C++/a.exe [New Thread 10860.0x2e0c] [New Thread 10860.0x3e64] [New Thread 10860.0x3e94] [New Thread 10860.0x8] Temporary breakpoint 1, main () at test3.cpp:32 32 A a; (gdb) n 33 B b; (gdb) 51return0; (gdb) p a $1 = {_vptr.A = 0x405178 <vtable for A+8>, a = 4194432} (gdb) p (int*)*((int*)0x405178) $2 = (int *) 0x403c08 <A::f()> (gdb) p (int*)*((int*)0x405178 + 1) $3 = (int *) 0x403c3c <A::g()> (gdb) p (int*)*((int*)0x405178 + 2) $4 = (int *) 0x0 (gdb) p b $5 = {<A> = {_vptr.A = 0x405188 <vtable for B+8>, a = 4200896}, b = 0} (gdb) p (int*)*((int*)0x405188) $6 = (int *) 0x403ca0 <B::f()> (gdb) p (int*)*((int*)0x405188+1) $7 = (int *) 0x403c3c <A::g()> (gdb) p (int*)*((int*)0x405188+2) $8 = (int *) 0x403cd4 <B::g1()> (gdb) p (int*)*((int*)0x405188+3) $9 = (int *) 0x3a434347 (gdb)
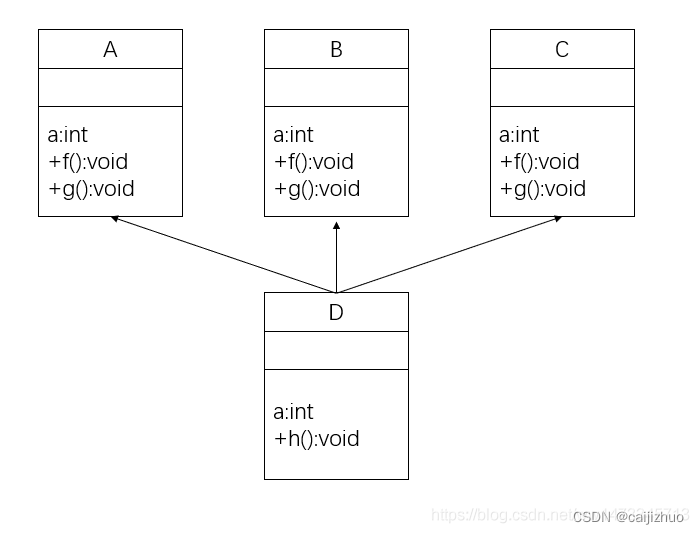
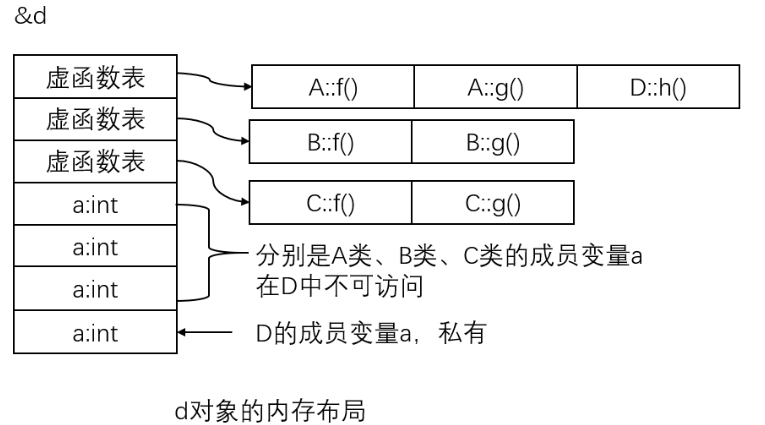
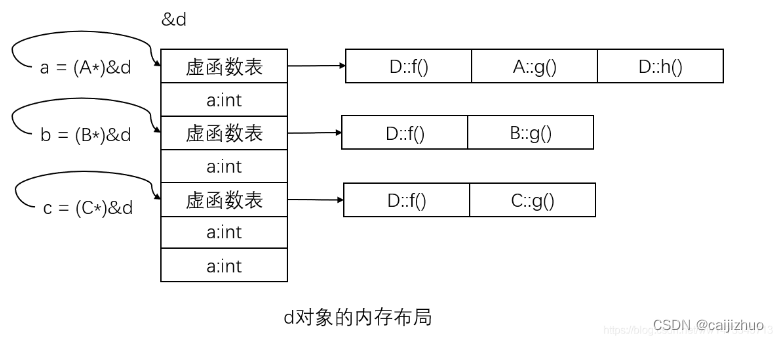
classD : public B, public C { public: D() { cout << "D()" << endl; } ~D() { cout << "~D()" << endl; } }; intmain(){ D d; // A* a = &d; // test.cc: In function ‘int main()’: // test.cc:46:13: error: ‘A’ is an ambiguous base of ‘D’ // A* a = &d; // ^ return0; }
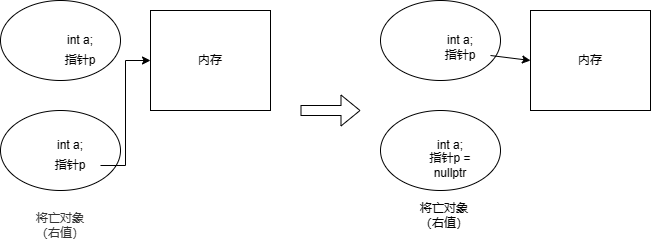
int t = 10; // t为左值 ++t; // t为左值,没有拷贝,这就是为什么 ++t 比 t++ 高效 t++; // t为右值,因为加之前的值是个将亡值,是个 t_copy,是个临时变量 int &&r = t; // 错误,右值不能绑定左值。
std::move()
实现代码
1 2 3 4 5 6 7 8 9
/** * @brief Convert a value to an rvalue. * @param __t A thing of arbitrary type. * @return The parameter cast to an rvalue-reference to allow moving it. */ template<typename _Tp> constexprtypename std::remove_reference<_Tp>::type&& move(_Tp&& __t)noexcept { returnstatic_cast<typename std::remove_reference<_Tp>::type&&>(__t); }
intmain(){ int a = 1; int b = 2; constint c = 1; constint d = 0; int &e = a; int &f = b; constint &g = c; constint &h = d; WithoutPerfectForward(a); // l + r = l WithoutPerfectForward(move(b)); // r + r = r WithoutPerfectForward(c); // const l + r = l WithoutPerfectForward(move(d)); // const r + r = r WithoutPerfectForward(e); // l ref + r = l WithoutPerfectForward(move(f)); // r ref + r = r WithoutPerfectForward(g); // const l ref + r = l WithoutPerfectForward(move(h)); // const r ref + r = r }
intmain(){ int a = 1; int b = 2; constint c = 1; constint d = 0; int &e = a; int &f = b; constint &g = c; constint &h = d; WithoutPerfectForward(a); // l + r WithoutPerfectForward(move(b)); // r + r WithoutPerfectForward(c); // const l + r WithoutPerfectForward(move(d)); // const r + r WithoutPerfectForward(e); // l ref + r WithoutPerfectForward(move(f)); // r ref + r WithoutPerfectForward(g); // const l ref + r WithoutPerfectForward(move(h)); // const r ref + r }
结果:
1 2 3 4 5 6 7 8 9
@└────> # ./a.out int & called! int & called! const int & called! const int & called! int & called! int & called! const int & called! const int & called!
可以看到虽然在函数 WithoutPerfectForward 中是右值,但是传给下一个函数的时候又默认都是左值了。虽然参数 t 是右值类型的,但此时 t 在内存中已经有了位置,所以 t 其实是个左值。
intmain(){ int a = 1; int b = 2; constint c = 1; constint d = 0; int &e = a; int &f = b; constint &g = c; constint &h = d; WithoutPerfectForward(a); // l + r WithoutPerfectForward(move(b)); // r + r WithoutPerfectForward(c); // const l + r WithoutPerfectForward(move(d)); // const r + r WithoutPerfectForward(e); // l ref + r WithoutPerfectForward(move(f)); // r ref + r WithoutPerfectForward(g); // const l ref + r WithoutPerfectForward(move(h)); // const r ref + r }
结果:
1 2 3 4 5 6 7 8 9
@└────> # ./a.out int & called! int && called! const int & called! const int && called! int & called! int && called! const int & called! const int && called!
/** * @brief Forward an lvalue. * @return The parameter cast to the specified type. * * This function is used to implement "perfect forwarding". */ template<typename _Tp> constexpr _Tp&& forward(typename std::remove_reference<_Tp>::type& __t)noexcept { returnstatic_cast<_Tp&&>(__t); }
/** * @brief Forward an rvalue. * @return The parameter cast to the specified type. * * This function is used to implement "perfect forwarding". */ template<typename _Tp> constexpr _Tp&& forward(typename std::remove_reference<_Tp>::type&& __t)noexcept { static_assert(!std::is_lvalue_reference<_Tp>::value, "template argument" " substituting _Tp is an lvalue reference type"); returnstatic_cast<_Tp&&>(__t); }
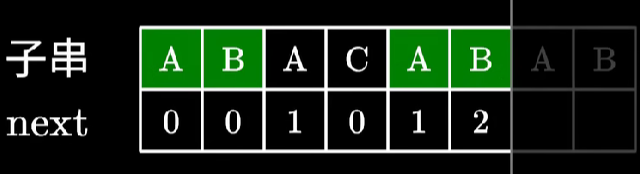
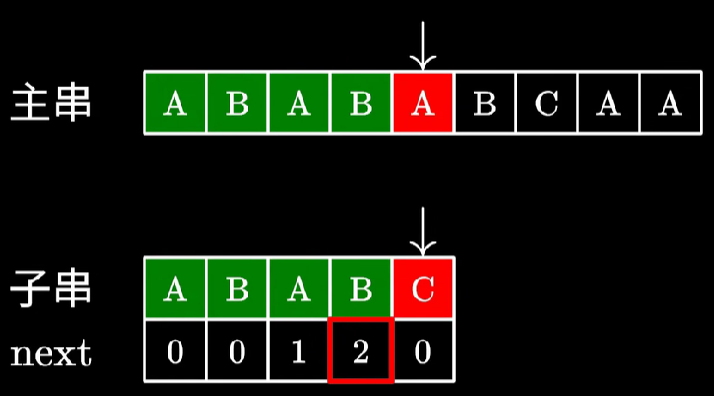
next 数组的本质是寻找子串中“相同前后缀的长度,并且最长”。并且不能是字符串本身。举个例子而言,如下所示:
A
B
A
B
C
0
0
1
2
0
第 1位 A 只有一个字符,不能是字符串本身,为 0;
第 2位 B 和 A 比较,不相等,为 0;
第 3位 A 和 A 比较,相等,所以相同前缀为 1;
第 4位 B 和前缀为 1 后的 B 比较,相等,和前缀组成了 AB 的相同模式的串,所以相同前缀为 2;
第 5 位 C 和前缀为 2 后的 A 比较,不相等,和前缀长度为 0 的比,相同前缀为0;
关于最长前缀的理解是,如下图所示。
最后一位的 A 很显然可以和 ABA 组成长度为 3 的相同前缀,也可以自己 A 组成长度为 1 的相同前缀。这种情况下选择较大的那个值。
求解next数组
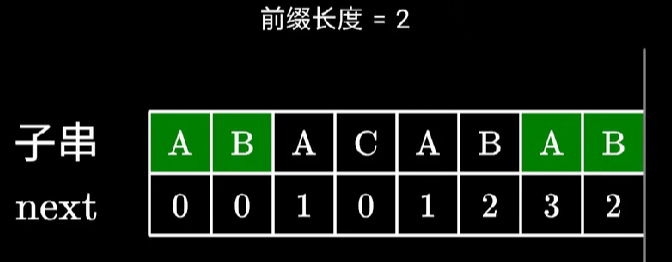
next 数组求解的本质是动态规划。假设我们已经知道当前数字的共同前后缀了,如下图所示。
接下来求第 i 位的 next 数组,分为两种情况。
下一位也和前缀相等
那就很明显等于 next[i−1] 加上 1。
下一位和前缀不相等
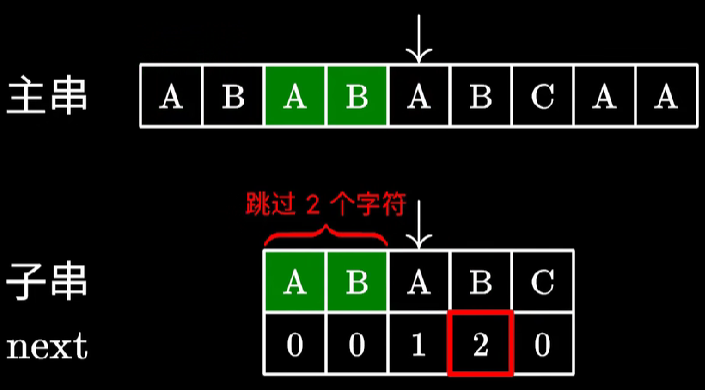
这里不是直接等于 0 哦。如下图所示
虽然 ABAB 和 ABAC 并不相等,但是也不能直接设为 0。因为这个新来的 B 可以和前面的 A 组成 AB,达到 2 的长度。那么这个数难道要暴力求解吗?其实不然。此时第 i−1 位的 next 的可利用的值在前缀的 next 数组中可以得到答案,在本图中为 next[2],即是 1。此时修改前缀长度为 next[2],则又回到了最开始的状况,匹配长度为 1 并且匹配下一位,下一位 B 相等,所以 next[i] 为 1+1=2。
代码如下: